
For example, if you want to get regular updates on your favorite products for discount offers or you want to automate the process of downloading episodes of your favorite season one by one, and the website doesn’t have any API for it then the only choice you’re left with is web scraping.Web scraping may be illegal on some websites, depending on whether a website allows it or not. Websites use “robots.txt” file to explicitly define URLs that are not allowed to be scrapped. You can check whether if website allows it or not by appending “robots.txt” with the website’s domain name. For example, https://www.google.com/robots.txt
In this article, we’ll use Python for scraping because its very easy to setup and use. It has many built-in and third party librariaries that can be used for scraping and organizing data. We’ll use two Python libraries “urllib” to fetch the webpage and “BeautifulSoup” to parse the webpage to apply programming operations.
How Web Scraping works?
We send a request to the webpage, from where you want to scrape the data. Website will respond to the request with HTML content of the page. Then, we can parse this webpage to BeautifulSoup for further processing. To fetch the webpage, we’ll use “urllib” library in Python.
Urllib will download the web page content in HTML. We can’t apply string operations to this HTML web page for content extraction and further processing. We’ll use a Python library “BeautifulSoup” that will parse the content and extract the interesting data.
Scraping articles from Linuxhint.com
Now that we have an idea of how web scraping works, let’s do some practice. We’ll try to scrape article titles and links from Linuxhint.com. So open https://linuxhint.com/ in your browser.
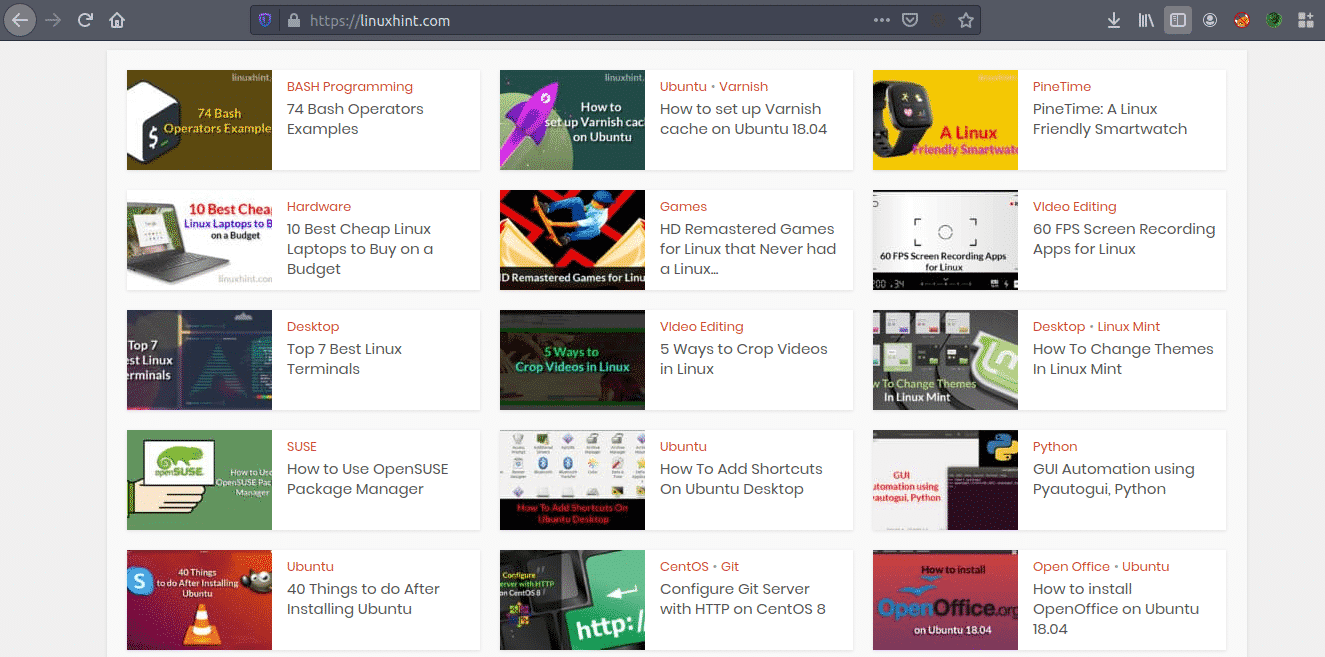
Now press CRTL+U to view the HTML source code of the web page.

Copy the source code, and go to https://htmlformatter.com/ to prettify the code. After prettifying the code, its easy to inspect the code and find interesting information.
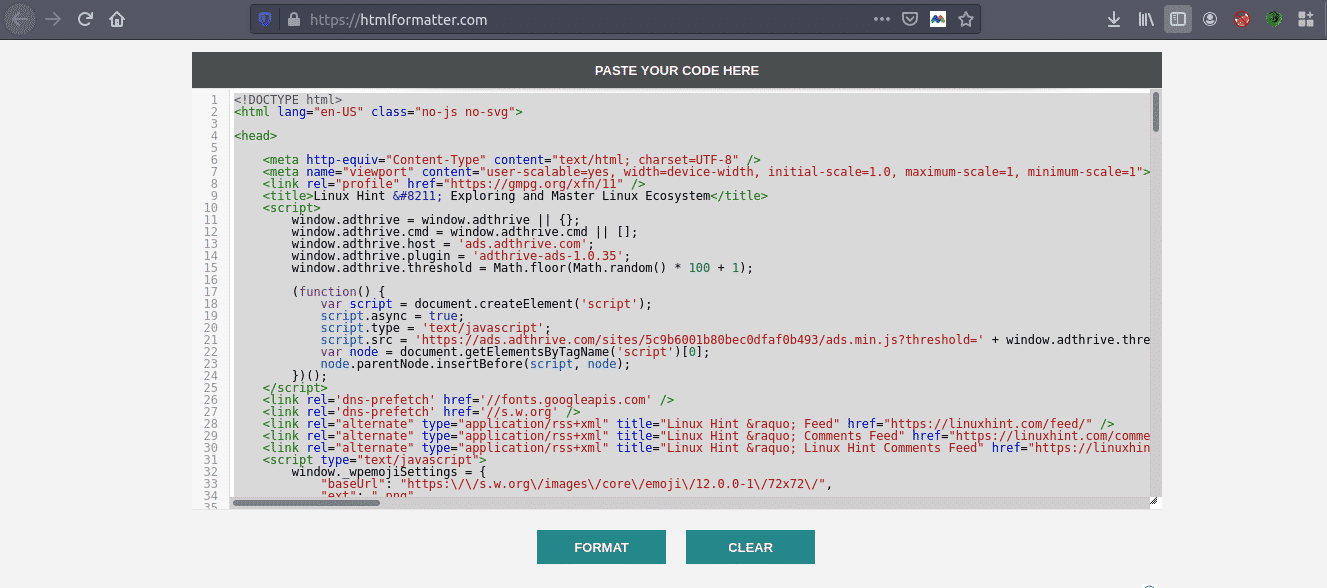
Now, again copy the formatted code and paste it in your favorite text editor like atom, sublime text etc. Now we’ll scrape the interesting information using Python. Type the following
pre-installed in Python
ubuntu@ubuntu:~$ sudo pip3 install bs4
ubuntu@ubuntu:~$ python3
Python 3.7.3 (default, Oct 7 2019, 12:56:13)
[GCC 8.3.0] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
>>> import urllib.request
//Import BeautifulSoup
>>> from bs4 import BeautifulSoup
//Enter the URL you want to fetch
>>> my_url = ‘https://linuxhint.com/’
//Request the URL webpage using urlopen command
>>> client = urllib.request.urlopen(my_url)
//Store the HTML web page in “html_page” variable
>>> html_page = client.read()
//Close the URL connection after fetching the webpage
>>> client.close()
//parse the HTML webpage to BeautifulSoup for scraping
>>> page_soup = BeautifulSoup(html_page, "html.parser")
Now let’s look at the HTML source code we just copied and pasted to find things of our interest.
You can see that the first article listed on Linuxhint.com is named “74 Bash Operators Examples”, find this in the source code. It is enclosed between header tags, and its code is
<span class="meta-category">
<a href="https://linuxhint.com/category/bash-programming/"
class="category-1561">BASH Programming</a></span>
<h2 class="entry-title">
<a href="https://linuxhint.com/bash_operator_examples/"
title="74 Bash Operators Examples">74 Bash Operators
Examples</a></h2>
</header>

The same code repeats over and over with the change of just article titles and links. The next article has the following HTML code
<span class="meta-category">
<a href="https://linuxhint.com/category/ubuntu/"
class="category-1343">Ubuntu</a> <span>•
</span> <a href="https://linuxhint.com/category/
varnish/" class="category-2078">Varnish</a></span>
<h2 class="entry-title">
<a href="https://linuxhint.com/varnish_cache_ubuntu_1804/"
title="How to set up Varnish cache on Ubuntu 18.04">
How to set up Varnish cache on Ubuntu 18.04</a></h2>
</header>
You can see that all articles including these two are enclosed in the same “<h2>” tag and use the same class “entry-title”. We can use “findAll” function in Beautiful Soup library to find and list down all “<h2>” having class “entry-title”. Type the following in your Python console
“entry-title”. The output will be stored in an array.
>>> articles = page_soup.findAll("h2" ,
{"class" : "entry-title"})
// The number of articles found on front page of Linuxhint.com
>>> len(articles)
102
// First extracted “<h2>” tag element containing article name and link
>>> articles[0]
<h2 class="entry-title">
<a href="https://linuxhint.com/bash_operator_examples/"
title="74 Bash Operators Examples">
74 Bash Operators Examples</a></h2>
// Second extracted “<h2>” tag element containing article name and link
>>> articles[1]
<h2 class="entry-title">
<a href="https://linuxhint.com/varnish_cache_ubuntu_1804/"
title="How to set up Varnish cache on Ubuntu 18.04">
How to set up Varnish cache on Ubuntu 18.04</a></h2>
// Displaying only text in HTML tags using text function
>>> articles[1].text
‘How to set up Varnish cache on Ubuntu 18.04’
Now that we have a list of all 102 HTML “<h2>” tag elements that contains article link and article title. We can extract both articles links and titles. To extract links from “<a>” tags, we can use the following code
>>> for link in articles[0].find_all(‘a’, href=True):
… print(link[‘href’])
…
https://linuxhint.com/bash_operator_examples/
Now we can write a for loop that iterates through every “<h2>” tag element in “articles” list and extract the article link and title.
… print(articles[i].text)
… for link in articles[i].find_all(‘a’, href=True):
… print(link[‘href’]+"n")
…
74 Bash Operators Examples
https://linuxhint.com/bash_operator_examples/
How to set up Varnish cache on Ubuntu 18.04
https://linuxhint.com/varnish_cache_ubuntu_1804/
PineTime: A Linux Friendly Smartwatch
https://linuxhint.com/pinetime_linux_smartwatch/
10 Best Cheap Linux Laptops to Buy on a Budget
https://linuxhint.com/best_cheap_linux_laptops/
HD Remastered Games for Linux that Never had a Linux Release…
https://linuxhint.com/hd_remastered_games_linux/
60 FPS Screen Recording Apps for Linux
https://linuxhint.com/60_fps_screen_recording_apps_linux/
74 Bash Operators Examples
https://linuxhint.com/bash_operator_examples/
…snip…
Similarly, you save this results to a JSON or CSV file.
Conclusion
Your daily tasks aren’t only file management or system command execution. You can also automate web related tasks like file download automation or data extraction by scraping the web in Python. This article was limited to only simple data extraction but you can do huge task automation using “urllib” and “BeautifulSoup”.

