In this lesson, that is what we intend to do. We will find out how values of different HTML tags can be extracted and also override the default functionality of this module to add some logic of our own. We will do this using the HTMLParser class in Python in html.parser module. Let’s see the code in action.
Looking at HTMLParser class
To parse HTML text in Python, we can make use of HTMLParser class in html.parser module. Let’s look at the class dfinition for the HTMLParser class:
The convert_charrefs field, if set to True will make all the character references converted to their Unicode equivalents. Only the script/style elements aren’t converted. Now, we will try to understand each function for this class as well to better understand what each function does.
- handle_startendtag This is the first function which is triggered when HTML string is passed to the class instance. Once the text reaches here, the control is passed to other functions in the class which narrows down to other tags in the String. This is also clear in the definition for this function: def handle_startendtag(self, tag, attrs):
self.handle_starttag(tag, attrs)
self.handle_endtag(tag) - handle_starttag: This method manages the start tag for the data it receives. Its definition is as shown below: def handle_starttag(self, tag, attrs):
pass - handle_endtag: This method manages the end tag for the data it receives: def handle_endtag(self, tag):
pass - handle_charref: This method manages the character references in the data it receives. Its definition is as shown below: def handle_charref(self, name):
pass - handle_entityref: This function handles the entity references in the HTML passed to it: def handle_entityref(self, name):
pass - handle_data:This is the function where real work is done to extract values from the HTML tags and is passed the data related to each tag. Its definition is as shown below: def handle_data(self, data):
pass - handle_comment: Using this function, we can also get comments attached to an HTML source: def handle_comment(self, data):
pass - handle_pi: As HTML can also have processing instructions, this is the function where these Its definition is as shown below: def handle_pi(self, data):
pass - handle_decl: This method handles the declarations in the HTML, its definition is provided as: def handle_decl(self, decl):
pass
Subclassing the HTMLParser class
In this section, we will sub-class the HTMLParser class and will take a look at some of the functions being called when HTML data is passed to class instance. Let’s write a simple script which do all of this:
class LinuxHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Start tag encountered:", tag)
def handle_endtag(self, tag):
print("End tag encountered :", tag)
def handle_data(self, data):
print("Data found :", data)
parser = LinuxHTMLParser()
parser.feed(”
‘
<h1>Python HTML parsing module</h1>
‘)
Here is what we get back with this command:
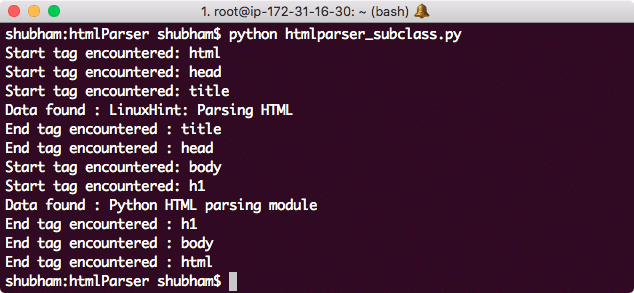
Python HTMLParser subclass
HTMLParser functions
In this section, we will work with various functions of the HTMLParser class and look at functionality of each of those:
from html.entities import name2codepoint
class LinuxHint_Parse(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Start tag:", tag)
for attr in attrs:
print(" attr:", attr)
def handle_endtag(self, tag):
print("End tag :", tag)
def handle_data(self, data):
print("Data :", data)
def handle_comment(self, data):
print("Comment :", data)
def handle_entityref(self, name):
c = chr(name2codepoint[name])
print("Named ent:", c)
def handle_charref(self, name):
if name.startswith(‘x’):
c = chr(int(name[1:], 16))
else:
c = chr(int(name))
print("Num ent :", c)
def handle_decl(self, data):
print("Decl :", data)
parser = LinuxHint_Parse()
With various calls, let us feed separate HTML data to this instance and see what output these calls generate. We will start with a simple DOCTYPE string:
‘"http://www.w3.org/TR/html4/strict.dtd">’)
Here is what we get back with this call:
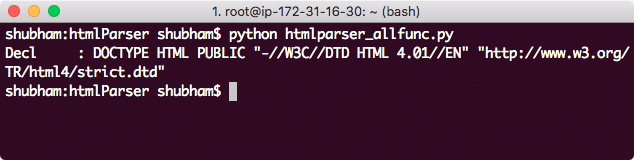
DOCTYPE String
Let us now try an image tag and see what data it extracts:
Here is what we get back with this call:

HTMLParser image tag
Next, let’s try how script tag behaves with Python functions:
‘alert("<strong>LinuxHint Python</strong>");</script>’)
parser.feed(‘<style type="text/css">#python { color: green }</style>’)
parser.feed(‘#python { color: green }’)
Here is what we get back with this call:

Script tag in htmlparser
Finally, we pass comments to the HTMLParser section as well:
‘<!– [if IE 9]>IE-specific content<![endif]–>’)
Here is what we get back with this call:
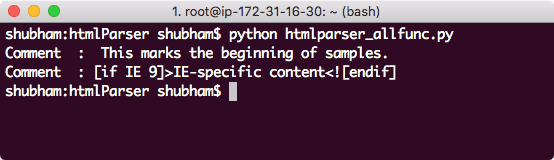
Parsing comments
Conclusion
In this lesson, we looked at how we can parse HTML using Python own HTMLParser class without any other library. We can easily modify the code to change the source of the HTML data to an HTTP client.
Read more Python based posts here.