
Uniq usage
Here’s how the base structure of “uniq” commands looks like.
For example, let’s check out the content of “duplicate.txt”. Of course, it contains a lot of duplicate text content for the purpose of this article.

There are clearly duplicate contents, right? Let’s filter them through “uniq”.
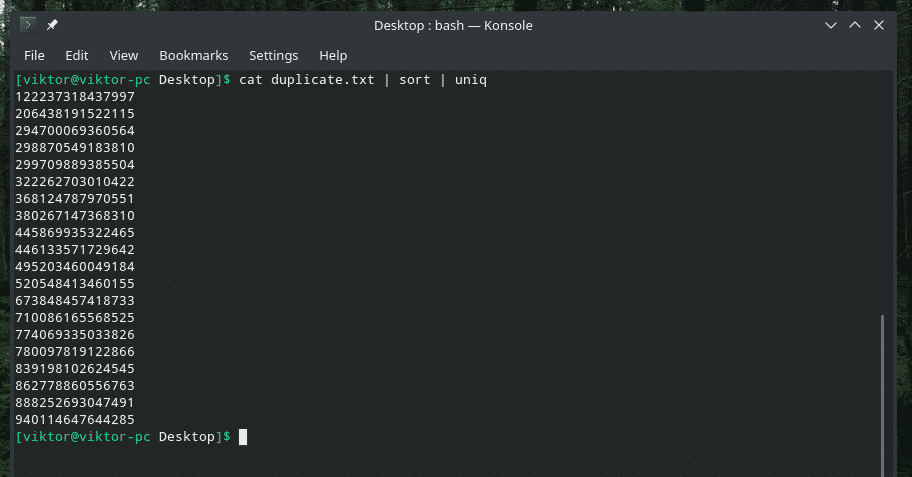
The output looks so better with only the unique values, right?
However, you just don’t need to use the piping method to do the job. “uniq” can directly work on the files as well.
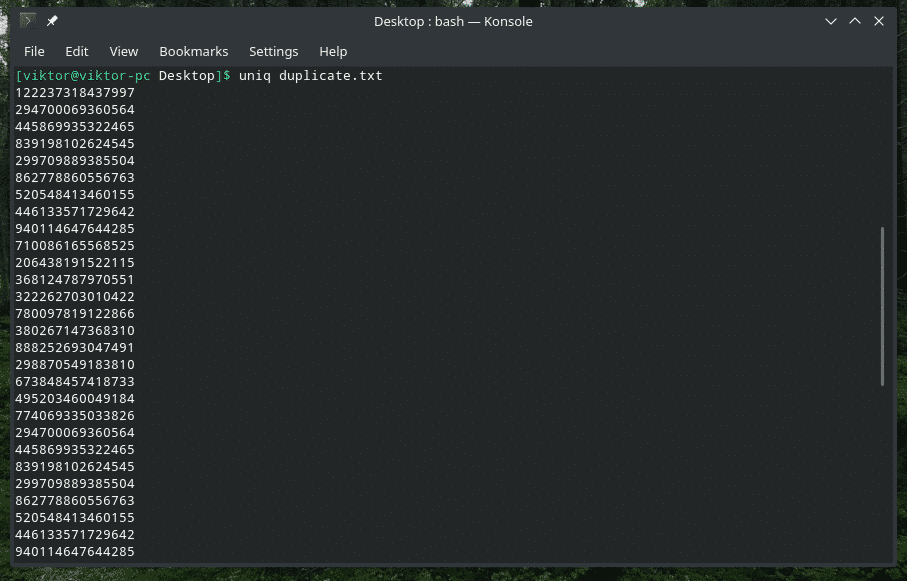
Deleting duplicate content
Yes, deleting the duplicate content from the input and keeping the first occurrence only is the default behavior of “uniq”. Note that this duplicate deletion only occurs when “uniq” finds concurrent duplicate items.
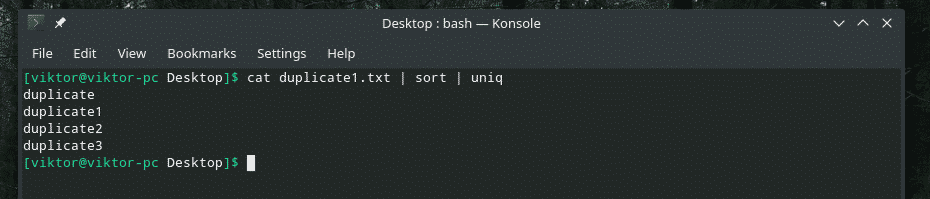
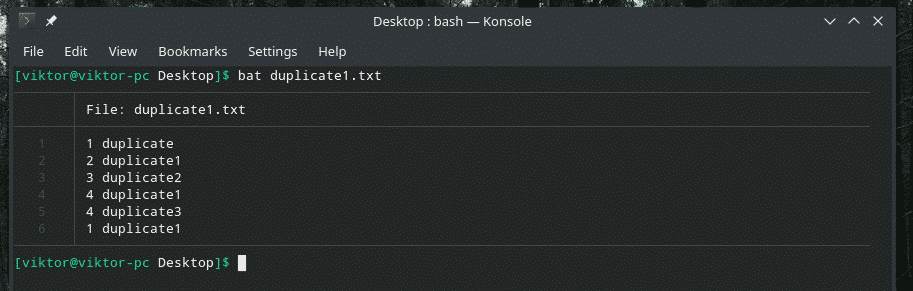
Let’s check out this example. I’ve created another “duplicate1.txt” file that contains duplicate items. However, they’re not adjacent to each other.

Now, filter this output using “uniq”.
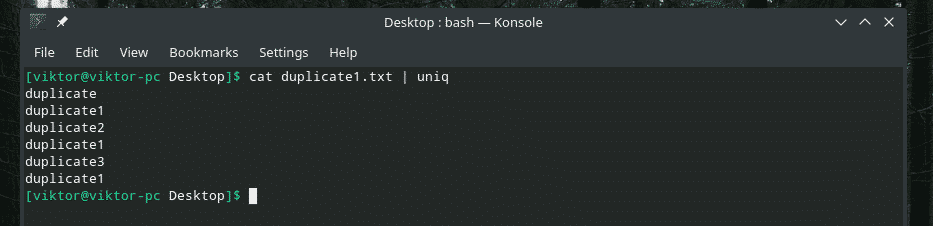
All the duplicate contents are there! That’s why if you’re working with something similar to this, pipe the content through “sort” to make sure that all the contents are sorted and duplicates are adjacent to each other.
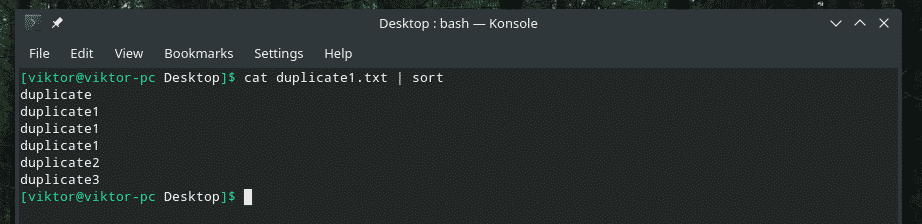
Now, “uniq” will do its job normally.
Number of repetitions
If you want, you can check out how many times a line is repeated in the content. Just use the “-c” flag with “uniq”.
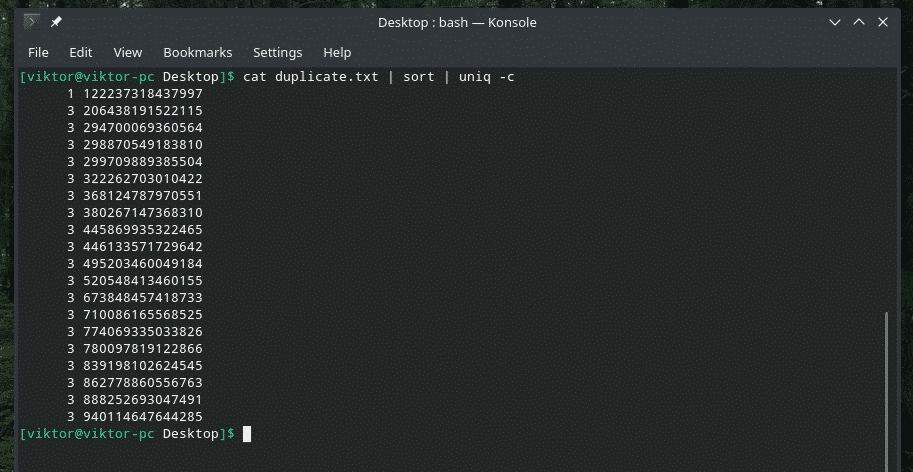
Note: “uniq” will also do its regular job of deleting the duplicate ones.
Printing duplicate lines
Most of the times, we want to get rid of the duplicates, right? This time, how about just checking out what’s duplicate?
Yes, “uniq” is also able to do that. In this case, you have to use the “-D” option. I’ll be using “sort” in-between to have a better, more refined result.
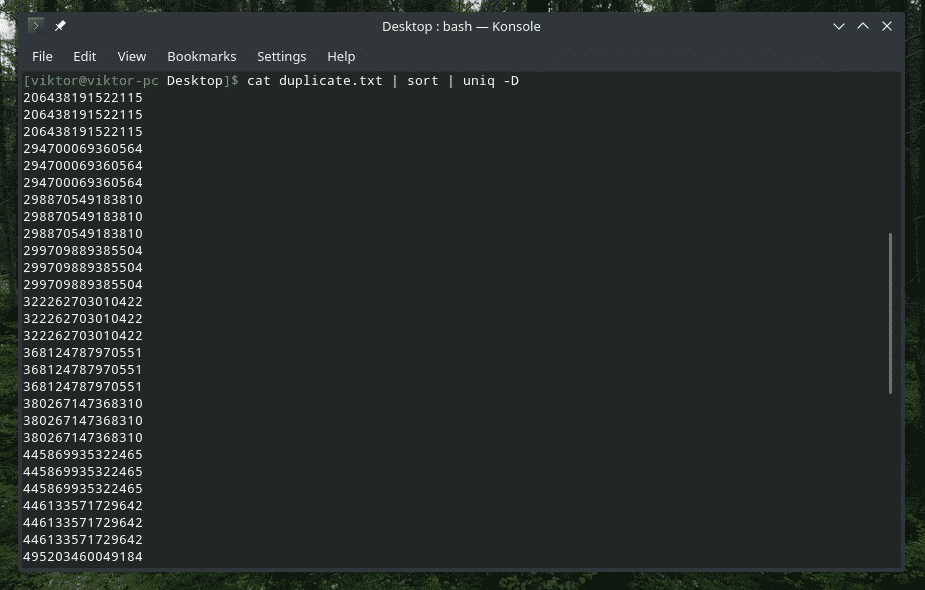
WOW! That’s a LOT of duplicates! However, all duplicates are clustered together, making it difficult to navigate through. How about adding a little gap in-between?
Here, there are 3 different methods available: none (default value), prepend and separate.

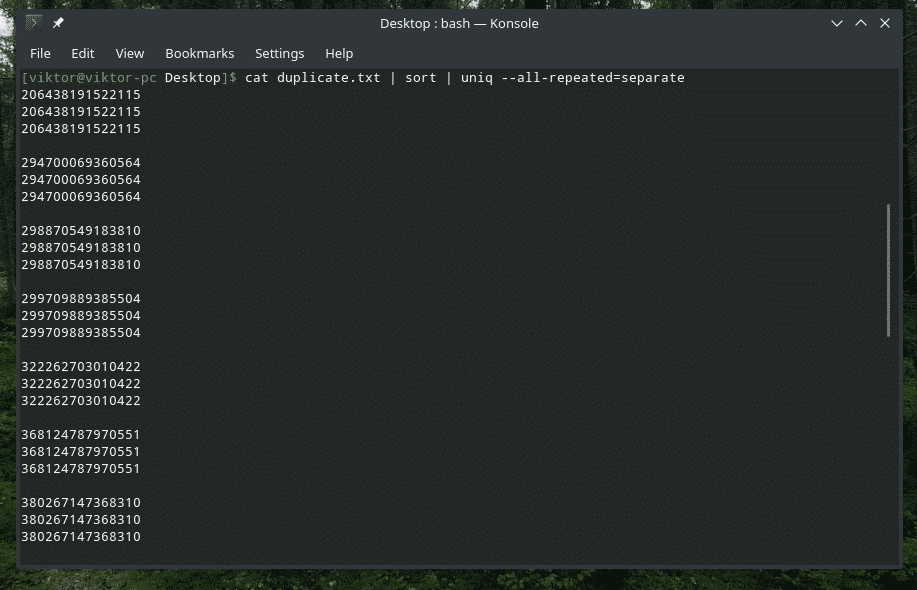
Now, it looks better.
Skipping uniqueness check
In many cases, the uniqueness has to be checked by a different part of the line.
Let’s understand this by example. In the file duplicate1.txt, let’s say that the duplication is determined by the second part. How do you tell “uniq” to do that? Generally, it checks for the first field (by default). Well, we can also do that, too. There’s this “-f” flag to do just the job.
cat duplicate1.txt | sort -k 2 | uniq -f 1
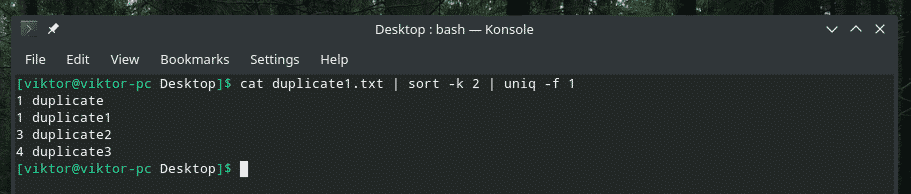
If you’re wondering with the “sort” flag, it’s to tell “sort” to sort based on the second column.
Display all lines but separate duplicates
According to all the examples mentioned above, “uniq” only keeps the first occurrence of the duplicated content and removes the rest. How about removing the duplicate contents altogether? Yes, using the flag “-u”, we can force “uniq” to keep the non-repetitive lines only.
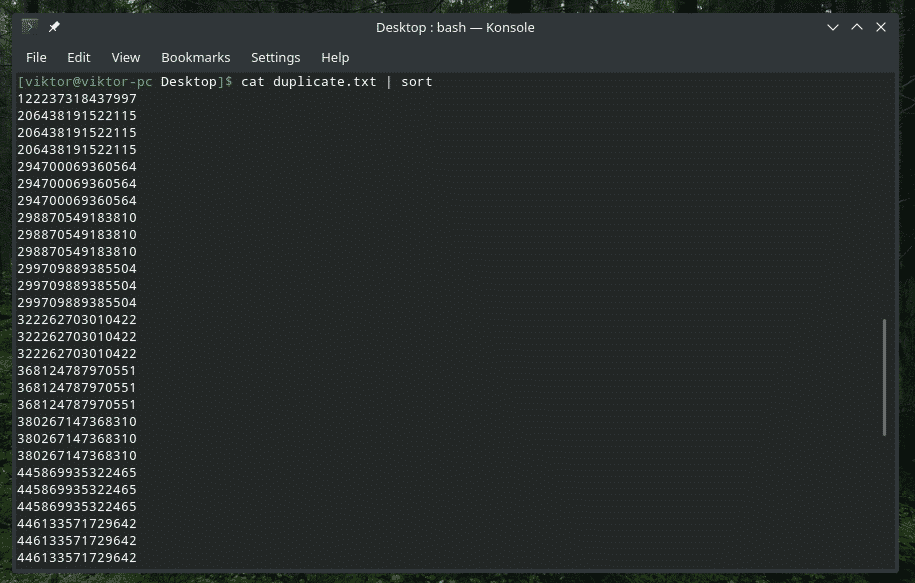

Hmm, too many duplicates now gone…
Skip initial characters
We discussed how to tell “uniq” to do its job for other fields, right? It’s time for starting the check after a number of initial characters. For this purpose, the “-s” flag accompanied by the number of characters is going to tell “uniq” to do the job.

It’s similar to the example where “uniq” was to do its task in the second field only. Let’s see another example with this trick.
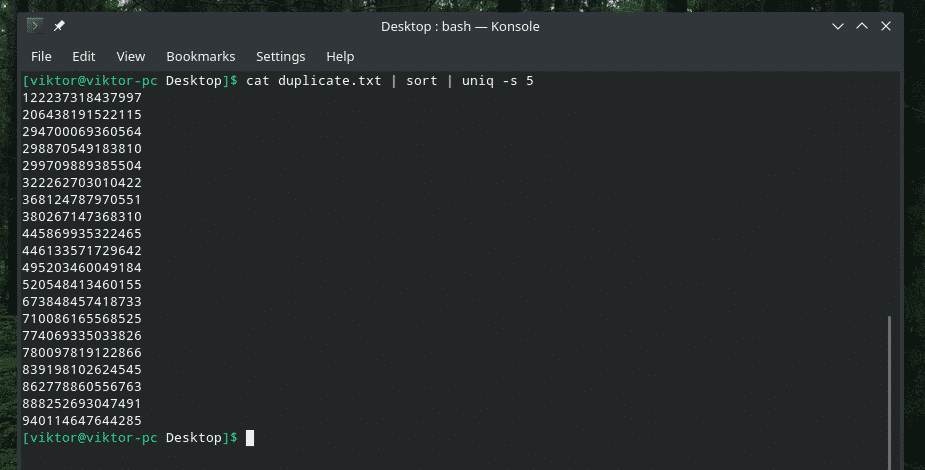
Check initial characters ONLY
Just like the way we told “uniq” to skip first couple characters, it’s also possible to tell “uniq” to just limit the check within the first couple characters. There’s a dedicated “-w” flag for this purpose.
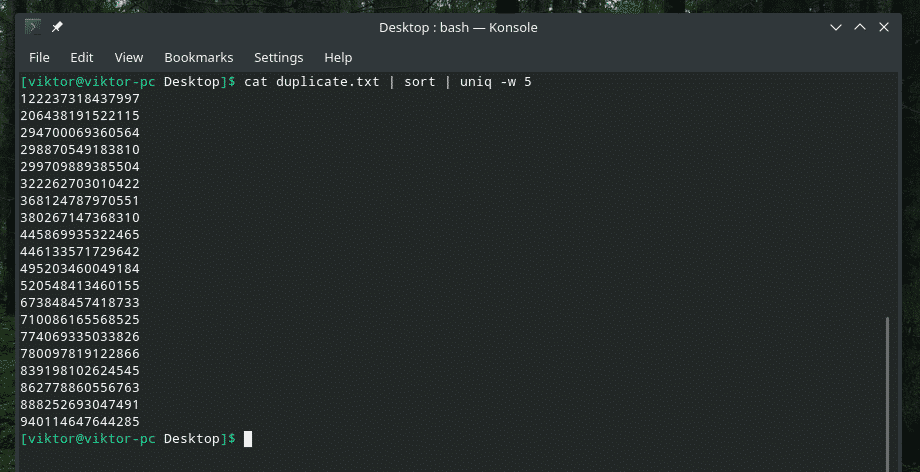
This command tells “uniq” to perform uniqueness check within the first 5 characters.
Let’s see another example of this command.

It wipes out all the other instances of “duplicate” entries because it did the uniqueness check on “dupli” part.
Case insensitivity
When checking for uniqueness, “uniq” also checks for the case of the characters. In some situations, case sensitivity doesn’t matter, so we can use the flag “-i” to make “uniq” case insensitive.
Here I present you the demo file.
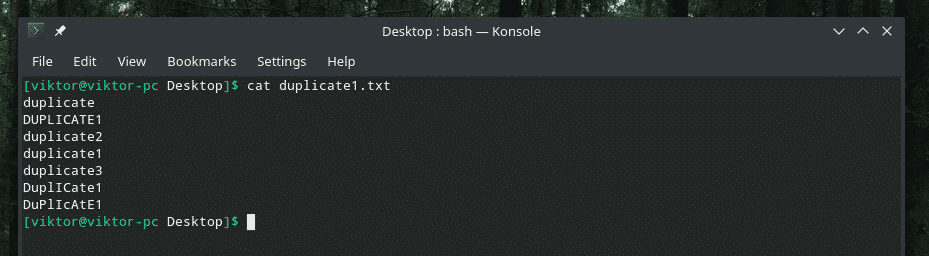
Some really clever duplication with a mixture of uppercase and lowercase letters, right? It’s time to call upon the strength of “uniq” to purge the mess!
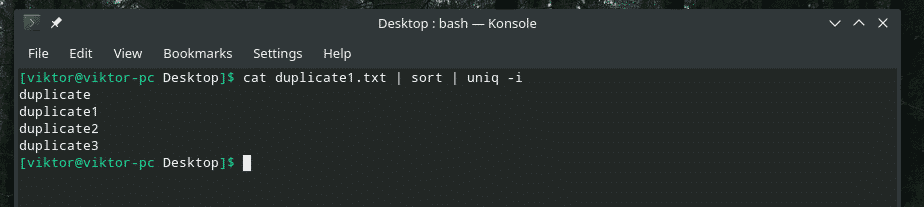
Wish granted!
NULL-terminated output
The default behavior of “uniq” is to end the output with a newline. However, the output can also be terminated with a NULL. That’s pretty useful if you’re going to use it in scripting. Here, the flag “-z” is what does the job.


Combining multiple flags
We learned a number of flags of “uniq”, right? How about combining them together?
For example, I’m combining the case insensitivity and number of repetition together.
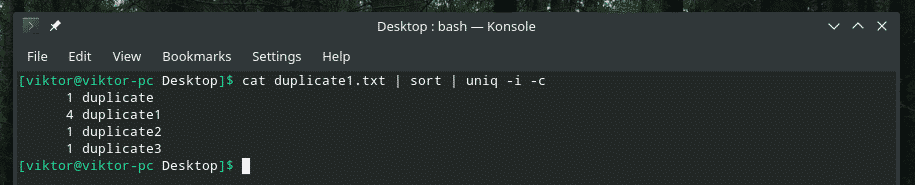
If you’re ever planning to mix multiple flags together, at first, make sure that they work the right way together. Sometimes, things just don’t work as they should.
Final thoughts
“uniq” is quite a unique tool that Linux offers. With so much powerful features, it can be useful in tons of ways. For the list of all the flags and their explanations, consult the man and info pages of “uniq”.

Enjoy!

