
A generic Linux distro offers access to a handful of really useful and simple compression mechanisms. This article will only focus on them.
Compression types
Compression is encoding and representing information using fewer bits than it originally was. In the case of file compression, a compression method utilizes its own algorithm and mathematical calculation to generate an output that’s generally less than the size of the original file. Because of how different compression works and the random nature of files, the mileage may vary greatly.
There are 2 types of compression.
- Lossy compression: This is a risky type of compression that doesn’t guarantee data integrity. Essentially, once compressed, there’s a risk that the original file can’t be reconstructed using the compressed archive.
A solid example of this type of compression is the well-known MP3 format. When an MP3 is created from the original audio file, it’s significantly smaller than the original source music file. This causes loss of some audio quality. - Lossless compression: This is the most widely used type of compression. Using a “lossless” compression method, the original file can be reconstructed from the compressed file. The compression methods I’ll discuss in this article are all lossless compression methods.
Linux compression
Majority of the compression methods are available from the tool tar. As for the “zip” compression, we’ll be using the zip tool. Assuming that your system already has these tools installed, let’s get started.
At first, we need a test file. Run the following command to create one.

It’ll create a text file with 20MB size.
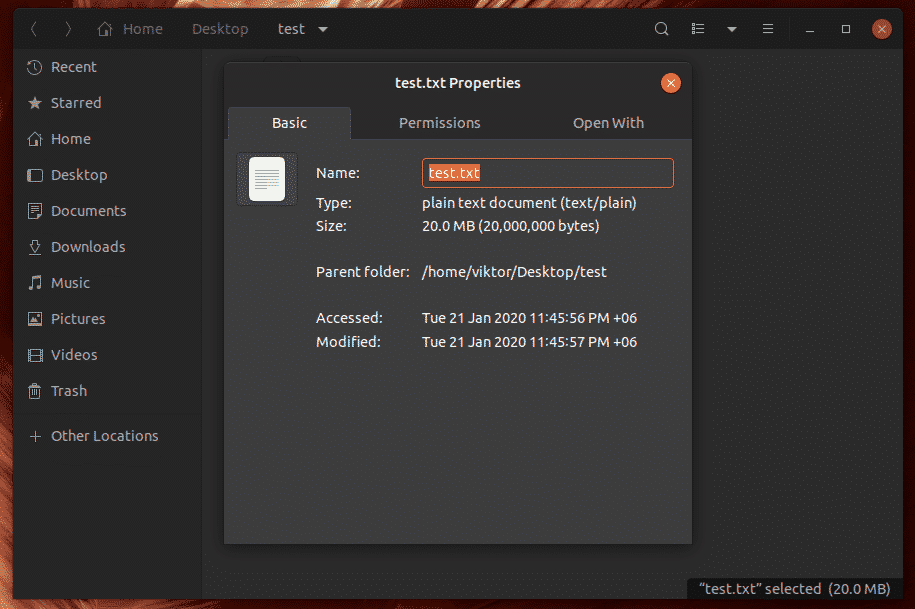
Now, let’s create 10 copies of the file. Together, it’s 200 MB.

Zip For Compression
Zip is quite common. For creating a zip file, the zip tool requires the following command structure.
To compress all the files under the test directory in a single zip file, run this command.

The input size was 200 MB. After compression, it’s now 152 MB!
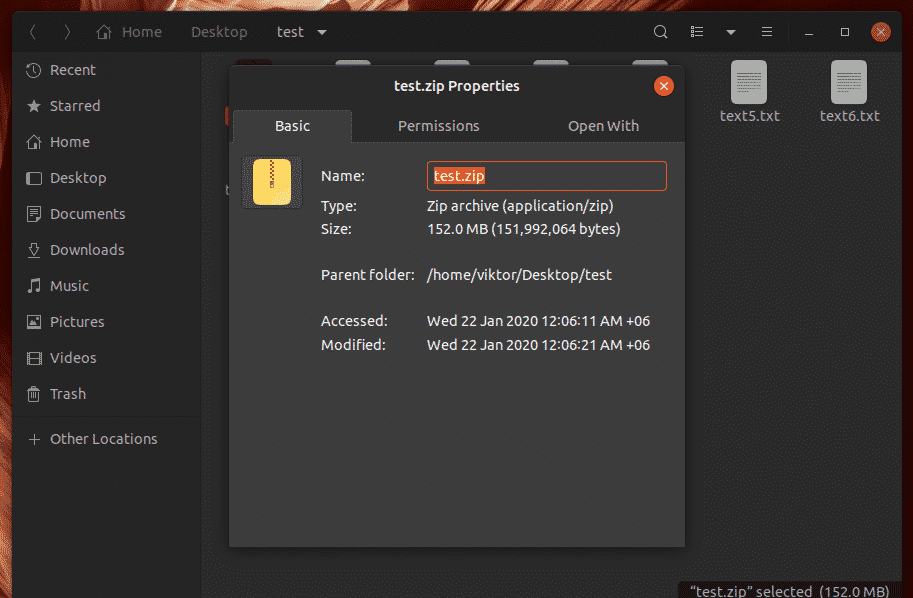
By default, the zip tool will apply the DEFLATE compression. However, it’s also capable of using bzip2 compression. Not only that, you can also create password-protected zip files! Learn more about zip.
Tar for Compression on Linux
Tar isn’t a compression method. Instead, it’s most often used for creating archives. However, it can implement a number of popular compression methods to the archive.
For handling tar (also known as “tarball”) archive, there’s the tar tool. Learn more about tar. Generally, the tar tool uses the following command structure.
To add the test files into a single tar archive, run the following command.

Here, the file size remains the same.

Gzip for Compression on Linux
GNU Zip or gzip is another popular compression method that, in my opinion, is better than the traditional zip because of its better compression. It’s an open-source product created by Mark Adler and Jean-Loup Gailly that was originally destined to replace the UNIX compress utility.
For managing gzip archives, there are 2 tools available: tar and gzip. Let’s check out both of them.
First, the gzip tool. Here’s how the gzip command structure looks.
For example, the following command will replace test1.txt with test1.txt.gz compressed file.

If you want to compress an entire directory using gzip, run this command. Here, the “-r” flag is for “recursive” compression. Gzip will go through all the folders and compress the individual file(s) in each of them.

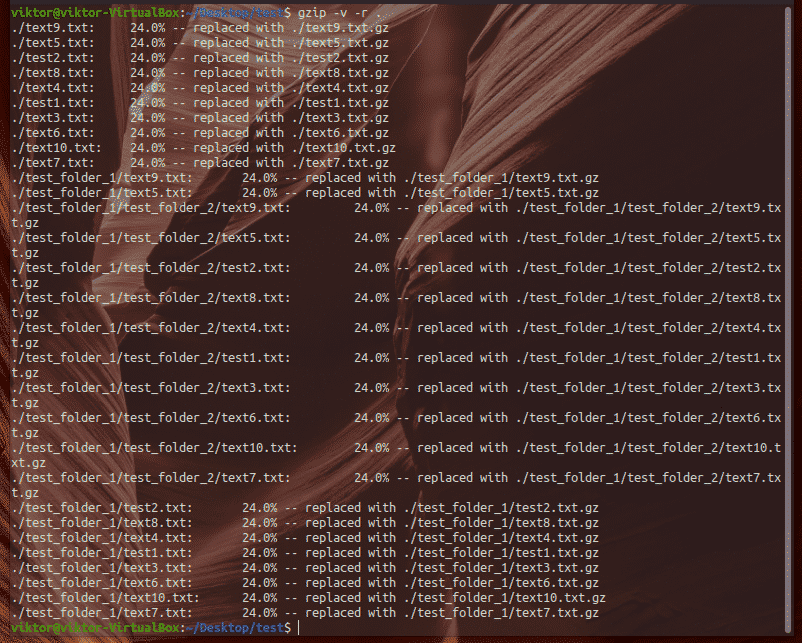
Gzip supports various compression strength value, starting from 1 (least compression, fastest) to 9 (best compression, slowest).

For better control over the output and ease-of-use, tar is better for the task. Run the following command.
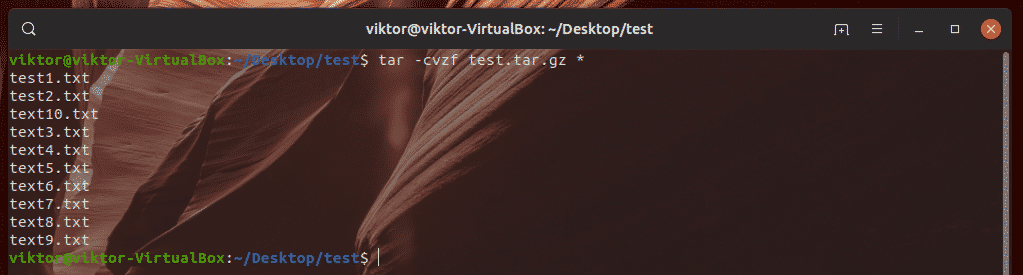
The result is similar to zip using DEFLATE, resulting in 152 MB after compression.

Bzip2 for Compression on Linux
Bzip2 is a free and open-source tool that uses the Burrows-Wheeler algorithm for compression. First introduced back in 1996, bzip2 is heavily used as an alternative to the gzip compression.
Like gzip, there are 2 tools to work with bzip2: tar and bzip2.
The bzip2 tool works similar to the gzip tool. It can only work with just a single file at a time. Here’s the command structure.
Let’s compress the test1.txt file. Here, the “-v” flag is for verbose mode.

Similar to gzip, bzip2 also supports different level of compression, starting from 1 (default, less memory usage) to 9 (extreme compression, high memory usage).

The better way of using bzip2 compression is by using tar. Use the following command.
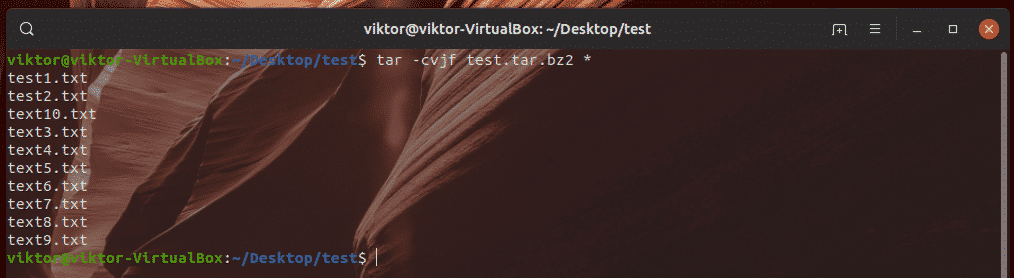
The compression is slightly improved than the previous ones. Now, the file size has shrunk to 151.7 MB.
XZ for Compression on Linux
It’s a relative newcomer in the field of compression. First released in 2009, it has seen a steady growth of usage since then.
The xz compression tool uses the LZMA2 algorithm that’s known for greater compression ratio compared to gzip and bzip2, making it a great choice when you want to save the maximum amount of disk space. However, this comes with the cost of higher memory requirements and time consumption.
File created by the XZ compression tool has the extension .xz. For compressing a single file, you can directly call the XZ tool.
For example, run the following command to compress the test1.txt file.

Similar to other compression methods mentioned, xz also supports various range of compression strength, starting from 1 (lowest compression, fastest) to 9 (best compression, slowest). If you don’t have any regard for time and just want to save space, then go for the extreme.

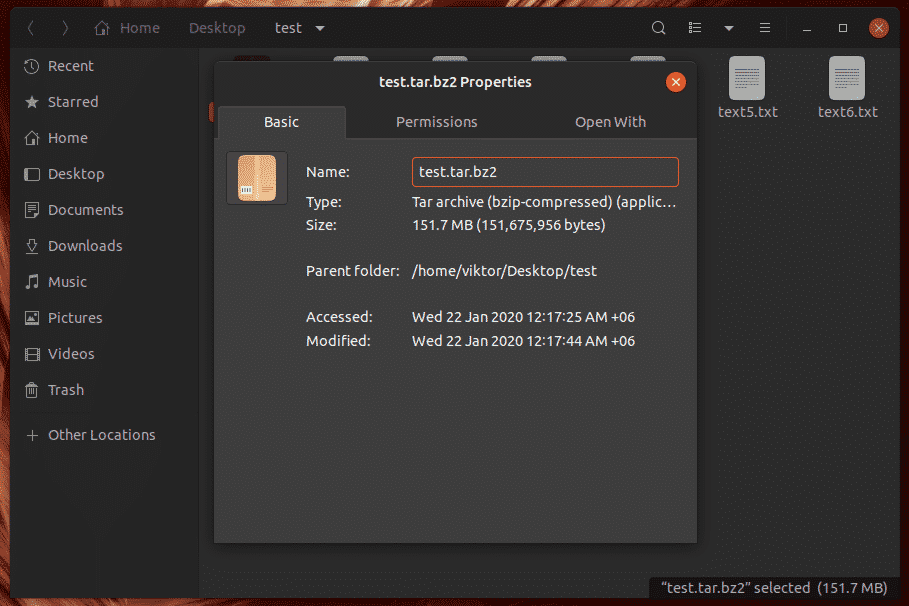
To create a compressed XZ file from all the test files, run this command.

Here, the output file size is 153.7 MB.
Extracting compressed archives
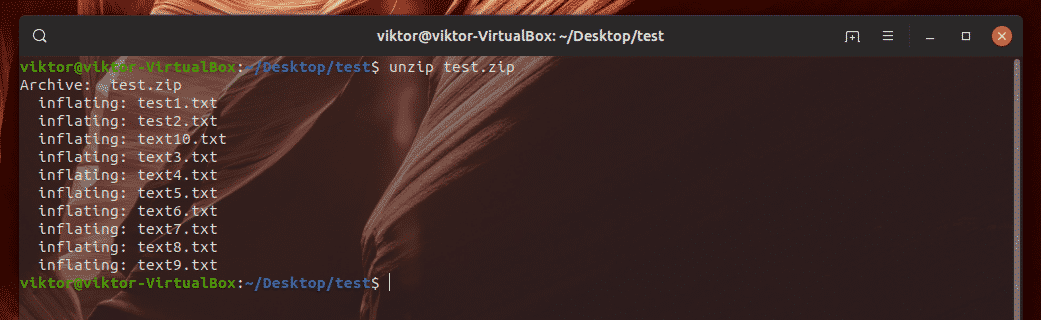
Extracting the archives we created is easier than creating them. To extract a zip file, use the following command structure.
To extract the zip archive we created, run this command. This will extract all the contents in the same directory.
For extracting tar, tar.gz, tar.bz2 and tar.xz archives, we have to use the tar tool. The following tar command is applicable for extracting all of them.
For example, let’s extract all the files from the bz2 compressed archive.

To decompress a gzip (not tar.gz) file, run this command.

Similarly, the following command will decompress bzip2 archive.

Same command structure applies for xz archive.

Final thoughts
Hopefully, now you have enough knowledge to handle the compression tasks in different circumstances. Depending on the specific requirement, all the compression methods offer very attractive features.
One important thing to note is, the compression result won’t be the same all the time. With different data input, the output will be different. For example, in some cases, xz can offer insane compression result whereas in this example, it didn’t. Same goes for other methods.
To learn more in-depth about these tools, check out their respective man page.
