
LinuxHint already published a tutorial explaining how to install and understand Tesseract’s training.
This tutorial shows Tesseract’s installation process in Debian/Ubuntu systems but won’t extended on training functionalities, if you aren’t familiarized with this software reading the mentioned article may be a good introduction. Then we will show you how to process a GIF image with Tesseract to get the text out of it.
Tesseract installation:
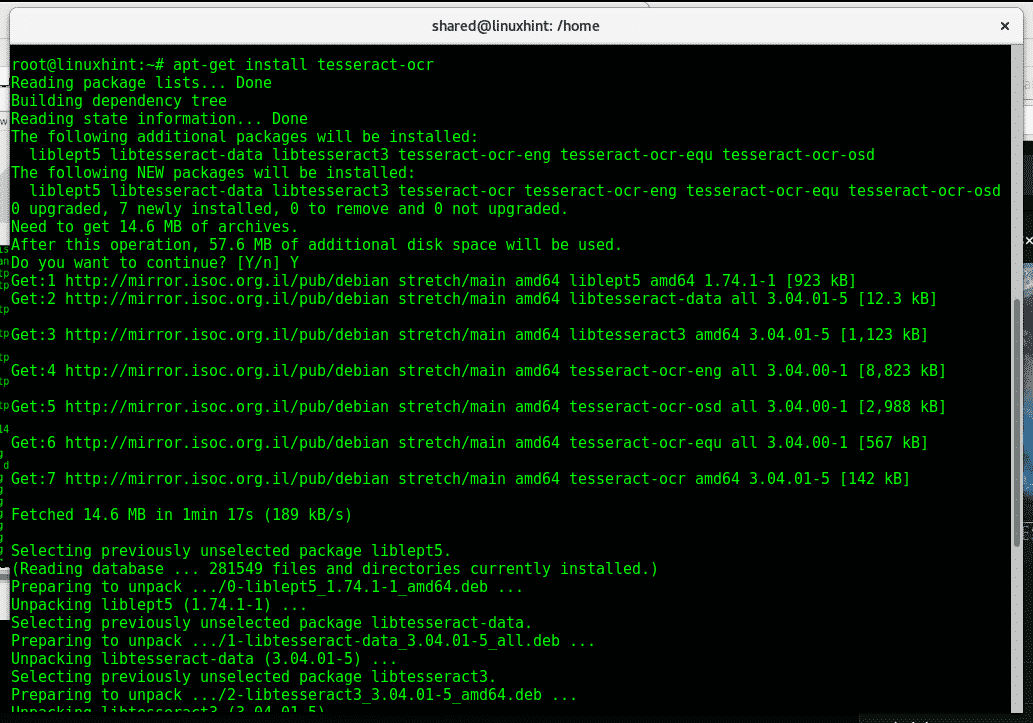
Run:
Now you need to install imagemagick which is an image converter.

Once installed we can already test Tesseract, to test it I found a gif licensed for reuse.
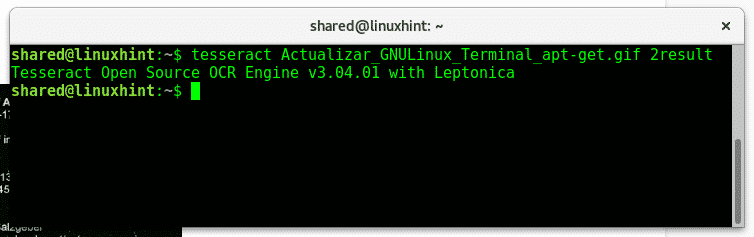
Now lets see what happens when we run tesseract on the gif image:

Now do a “less” on 1result.txt
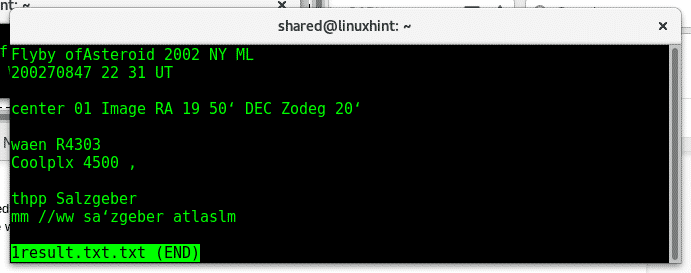
Here is the image with it’s text:

In this Tesseract ́s default settings are pretty accurate, usually to get such accuracy it requires training. Let’s try another free image I found on Wiki Commons, after downloading it run:
Now check the file’s content.

That’s was the result while the original image’s content was:
In order to improve the character recognition we have many options and steps to follow which were detailed in our previous tutorial: border removal, noise removal, size optimization and page rotation among other functions like crop.
For this tutorial we’ll use textcleaner, a script developed by Fred’s ImageMagick Scripts.
Download the script and run:
Actualizar_GNULinux_Terminal_apt-get.gif test.gif

Note: before running the script give it execution permissions by running “chmod +x textcleaner” as root or with sudo prefix.
Where:
textcleaner: calls the program
-g: Convert the image to grayscale
-e: enache
-f: filtersize
-s: sharpamt,amount of pixel sharpening to be applied to the result.
For information and examples of use with textcleaner visit http://www.fmwconcepts.com/imagemagick/textcleaner/index.php
As you see textcleaner changed the background color, increasing the contrast between the font and background.
If we run tesseract probably the result will be different:


As you see the result really improved even when it isn’t fully accurate.
The command convert provided by imagemagick allows us to extract frames from gif images to be processed later by Tesseract, this is useful if there is extraible content in different frames of the gif image.
The syntax is simple:
The result will be generated as number of files as frames in the gif, in the provided example the results would be: output-0.jpg, output-1.jpg, output-2.jpg, etc.
Then you can process them with tesseract, instructing it to process all files with a wildcard saving the result in a single file by running:
Imagemagick has a huge variety of options to optimize images and there is not a generic mode, for each kind of scenario you should read convert’s command man page.
I hope you found this tutorial on Tesseract resulted useful.

