What is Apache Solr
Apache Solr is one of the most popular NoSQL databases which can be used to store data and query it in near real-time. It is based on Apache Lucene and is written in Java. Just like Elasticsearch, it supports database queries through REST APIs. This means that we can use simple HTTP calls and use HTTP methods like GET, POST, PUT, DELETE etc. to access data. It also provides an option to get data in the form of XML or JSON through the REST APIs.
Architecture: Apache Solr
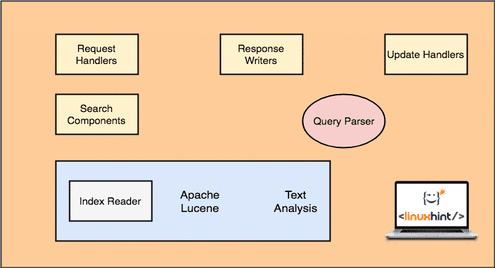
Before we can start working with Apache Solr, we must understand the components that constitutes Apache Solr. Let’s have a look at some components it has:

Apache Solr Architecture
Note that only major components for Solr are shown in above figure. Let’s understand their functionality here as well:
- Request Handlers: The requests a client makes to Solr are managed by a Request Handler. The request can be anything from adding a new record to update an index in Solr. Handlers identify the type of request from the HTTP method used with the request mapping.
- Search Component: This is one of the most important component Solr is known for. Search Component takes care of performing search related operations like fuzziness, spell checks, term queries etc.
- Query Parser: This is the component which actually parses the query a client passes to the request handler and breaks a query into multiple parts which can be understood by the underlying engine
- Response Writer: This component is responsible for managing the output format for the queries passed to the engine. Response Writer allows us to provide an output in various formats like XML, JSON etc.
- Analyzer/Tokenizer: Lucene Engine understands queries in the form of multiple tokens. Solr analyzes the query, breaks it into multiple tokens and passes it to the Lucene Engine.
- Update Request Processor: When a query is run and it performs operations like updating an index and data related to it, the Update Request Processor component is responsible for managing the data in the index and modifying it.
Getting Started with Apache Solr
To start using Apache Solr, it must be installed on the machine. To do this, read Install Apache Solr on Ubuntu.
Make sure you have an active Solr installation if you want to try examples we present later in the lesson and admin page is reachable on localhost:
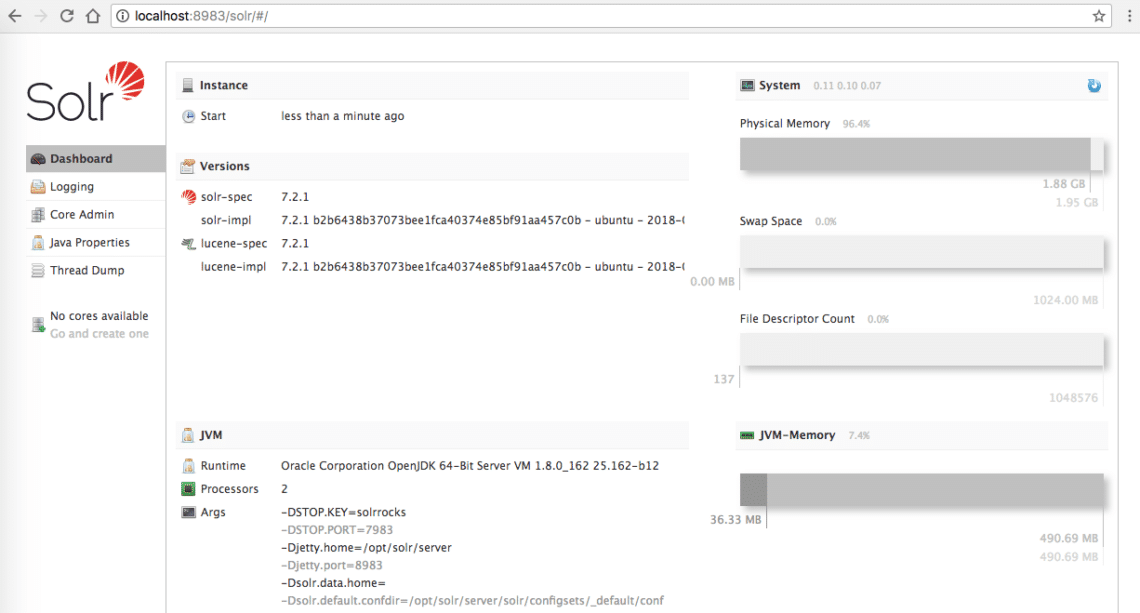
Apache Solr Homepage
Inserting Data
To start, let us consider a Collection in Solr which we call as linux_hint_collection. There is no need to explicitly define this collection as when we insert the first object, the collection will be made automatically. Let’s try our first REST API call to insert a new object into the collection named linux_hint_collection.
Inserting Data
‘http://localhost:8983/solr/linux_hint_collection/update/json/docs’ –data-binary ‘
{
"id": "iduye",
"name": "Shubham"
}’
Here is what we get back with this command:

Command to insert data into Solr
Data can also be inserted using the Solr Homepage we looked at earlier. Let’s try this here so that things are clear:
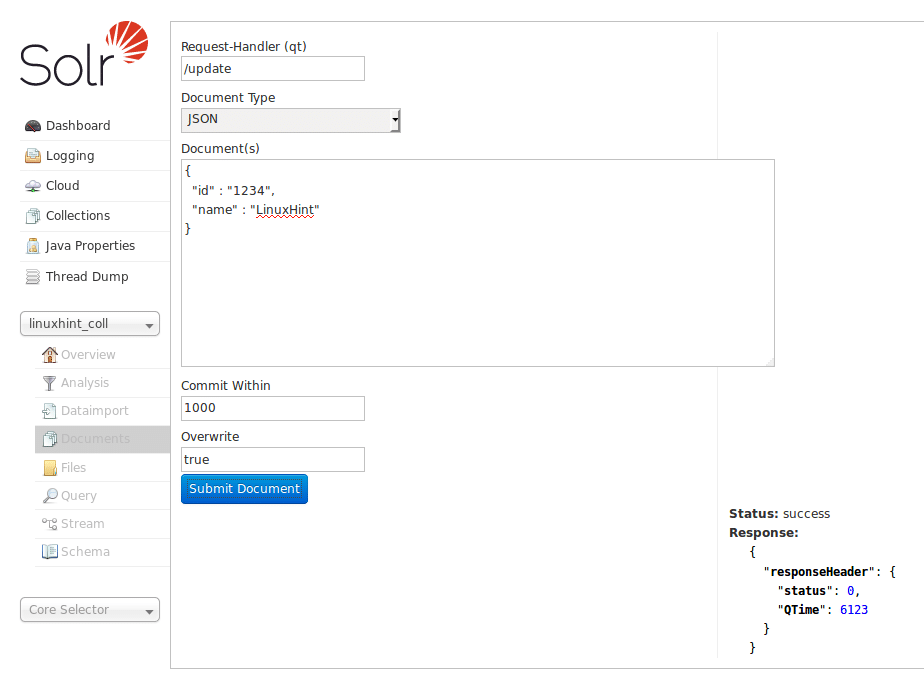
Insert Data via Solr Homepage
As Solr has an excellent way of interaction with HTTP RESTful APIs, we will be demonstrating DB interaction using the same APIs from now onwards and won’t focus much on inserting data through the Solr Webpage.
List All Collections
We can list all collections in Apache Solr using a REST API as well. Here is the command we can use:
List All Collections
Let’s see the output for this command:

We see two collections here which exist in our Solr installation.
Get Object by ID
Now, let us see how we can GET data from Solr collection with a specific ID. Here is the REST API command:
Get Object by ID
Here is what we get back with this command:

Get All Data
In our last REST API, we queried data using a specific ID. This time, we will get all data present in our Solr collection.
Get Object by ID
Here is what we get back with this command:
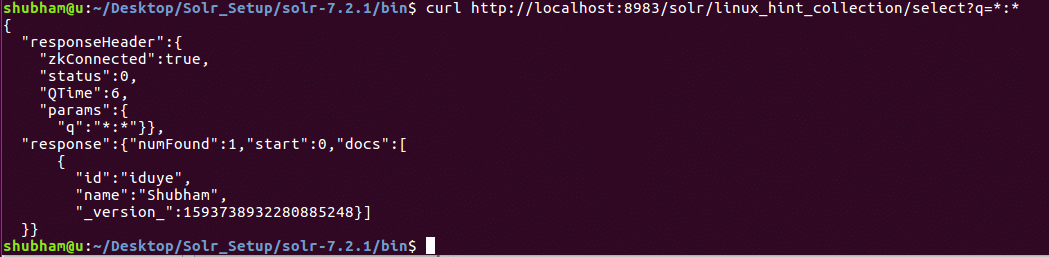
Notice that we have used ‘*:*’ in query parameter. This specifies that Solr should return all data present in the collection. Even if we have specified that all data should be returned, Solr understands that the collection might have large amount of data in it and so, it will only return first 10 documents.
Deleting All Data
Till now, all APIs we tried were using a JSON format. This time, we will give a try to XML query format. Using XML format is extremely similar to JSON as XML is self-descriptive as well.
Let’s try a command to delete all data we have in our collection.
Deleting All Data
Here is what we get back with this command:

Delete all data using XML query
Now, if we again try getting all data, we will see that no data is available now:

Get All data
Total Object Count
For a final CURL command, let’s see a command with which we can find the number of objects which are present in an index. Here is the command for the same:
Total Object Count
Here is what we get back with this command:

Count number of Objects
Conclusion
In this lesson, we looked at how we can use Apache Solr and pass queries using curl in both JSON and XML format. We also saw that the Solr admin panel is useful in same manner as all curl commands we studied.

