Please note that this is not an introductory lesson. Please read What is Apache Kafka and how does it work before you continue with this lesson to gain a deeper insight.
Topics in Kafka
A Topic in Kafka is something where a message is sent. The consumer applications which are interested in that topic pulls the message inside that topic and can do anything with that data. Up to a specific time, any number of consumer applications can pull this message any number of times.
Consider a Topic like LinuxHint’s Ubuntu Blog page. The lessons are put their till eternity and any number of enthusiast readers can come and read these lessons any number of times or move to the next lesson as they wish. These readers can be interested in other topics from LinuxHint as well.
Topic Partitioning
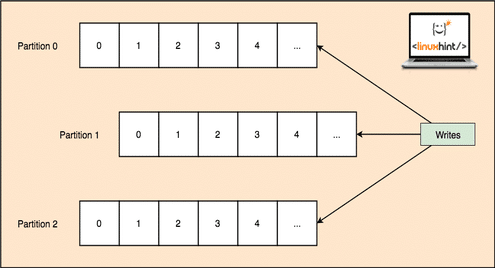
Kafka is designed to manage heavy applications and queue a large number of messages which are kept inside a topic. To ensure high fault tolerance, each Topic is divided into multiple topic partitions and each Topic Partition in managed on a separate node. If one of the nodes go down, another node can act as the topic leader and can server topics to the interested consumers. Here is how the same data is written to multiple Topic Partitions:
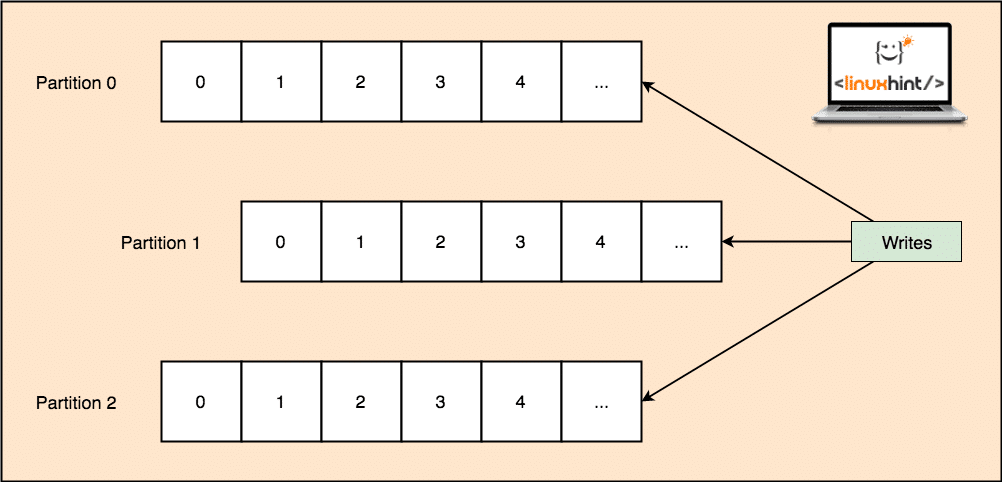
Topic Partitions
Now, the above image shows how same data is replicated across multiple partitions. Let’s visualise how different partitions can act as a leader on different nodes/partitions:
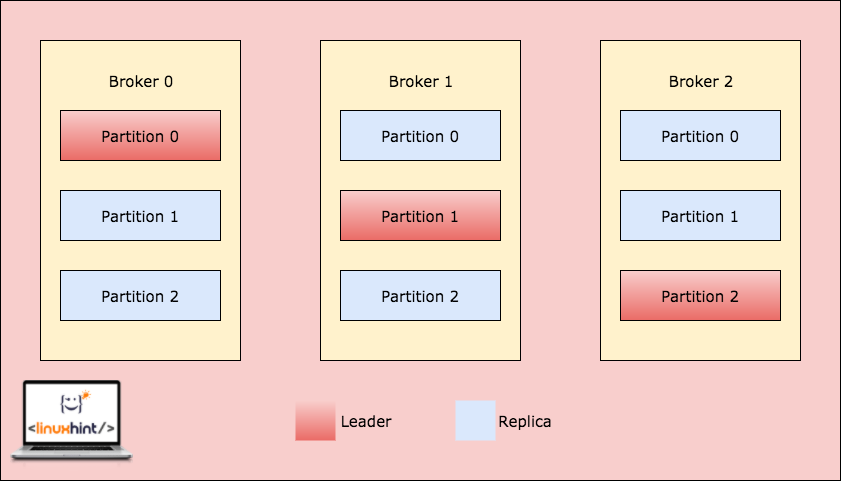
Kafka Broker Partitioning
When a client writes something to a topic at a position for which Partition in Broker 0 is the leader, this data is then replicated across the brokers/nodes so that message remains safe:

Replication across Broker Partitions
More Partitions, Higher Throughput
Kafka makes use of Parallelism to provide very high throughput to producer and consumer applications. Actually, through the same way, it also maintains its status of being a highly-fault tolerant system. Let’s understand how high throughput is achieved with Parallelism.
When a Producer application writes some message to a Partition in Broker 0, Kafka opens multiple threads in parallel so that message can be replicated across all the selected Brokers at the same time. On the Consumer side, a consumer application consumes messages from a single partition through a thread. The more the number of Partitions, the more consumer threads can be opened so that all of them can work in parallel as well. This means the more the number of partitions in a cluster, the more parallelism can be exploited, creating a very high throughput system.
More Partitions need more File Handlers
Just so you studied above how we can increase a Kafka system performance by just increasing the number of partitions. But we need to be careful with what limit are we moving towards.
Each Topic Partition in Kafka is mapped to a directory in the file system of the Server broker where it is running. Within that log directory, there will be two files: one for the index and another for the actual data per log segment. Currently, in Kafka, each broker opens a file handle for both the index and the data file of every log segment. This means that if you have 10,000 Partitions on a single Broker, this will result in 20,000 File Handlers running in parallel. Although, this is just about the configuration of the Broker. If the system on which the Broker is deployed has a high configuration, this will hardly be an issue.
Risk with high number of Partitions
As we saw in the images above, Kafka makes use of intra-cluster replication technique to replicate a message from a leader to the Replica partitions which lie in other Brokers. Both the producer and consumer applications read and write to a partition which is currently the leader of that partition. When a broker fails, the leader on that Broker will become unavailable. The metadata about who is the leader is kept in Zookeeper. Based on this metadata, Kafka will automatically assign the leadership of the partition to another partition.
When a Broker is shut down with a clean command, the controller node of Kafka cluster will move the leaders of the shutting down broker serially i.e. one at a time. if we consider moving a single leader takes 5 milliseconds, the unavailability of the leaders won’t disturb consumers as unavailability is for a very short period of time. But if we consider when the Broker is killed in an unclean manner and this Broker contains 5000 partitions and out of these, 2000 were the partition leaders, assigning new leaders for all these partitions will take 10 seconds which is very high when it comes to highly in-demand applications.
Conclusion
If we consider as a high-level thinker, more partitions in a Kafka cluster leads to a higher throughput of the system. Keeping this efficiency in mind, one also has to consider the configuration of the Kafka cluster we need to maintain, the memory we need to assign to that cluster and how we can manage the availability and latency if something goes wrong.
Read more Ubuntu based posts here and much more about Apache kafka as well.

