Anaconda is data science and machine learning platform for the Python and R programming languages. It is designed to make the process of creating and distributing projects simple, stable and reproducible across systems and is available on Linux, Windows, and OSX. Anaconda is a Python based platform that curates major data science packages including pandas, scikit-learn, SciPy, NumPy and Google’s machine learning platform, TensorFlow. It comes packaged with conda (a pip like install tool), Anaconda navigator for a GUI experience, and spyder for an IDE.This tutorial will walk through some of the basics of Anaconda, conda, and spyder for the Python programming language and introduce you to the concepts needed to begin creating your own projects.
Installation
There are many great articles on this site for installing Anaconda on different distro’s and native package management systems. For that reason, I will provide some links to this work below and skip to covering the tool itself.
Basics of conda
Conda is the Anaconda package management and environment tool which is the core of Anaconda. It is much like pip with the exception that it is designed to work with Python, C and R package management. Conda also manages virtual environments in a manner similar to virtualenv, which I have written about here.
Confirm Installation
The first step is to confirm installation and version on your system. The below commands will check that Anaconda is installed, and print the version to the terminal.
You should see similar results to the below. I currently have version 4.4.7 installed.
conda 4.4.7
Update Version
conda can be updated by using conda’s update argument, like below.
This command will update to conda to the most current release.
Downloading and Extracting Packages
conda 4.4.8: ########################################################### | 100%
openssl 1.0.2n: ######################################################## | 100%
certifi 2018.1.18: ##################################################### | 100%
ca-certificates 2017.08.26: ############################################ | 100%
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
By running the version argument again, we see that my version was updated to 4.4.8, which is the newest release of the tool.
conda 4.4.8
Creating a new Environment
To create a new virtual environment, you run the series of commands below.
You can see the packages that are installed into your new environment below.
certifi 2018.1.18: ##################################################### | 100%
sqlite 3.22.0: ######################################################### | 100%
wheel 0.30.0: ########################################################## | 100%
tk 8.6.7: ############################################################## | 100%
readline 7.0: ########################################################## | 100%
ncurses 6.0: ########################################################### | 100%
libcxxabi 4.0.1: ####################################################### | 100%
python 3.6.4: ########################################################## | 100%
libffi 3.2.1: ########################################################## | 100%
setuptools 38.4.0: ##################################################### | 100%
libedit 3.1: ########################################################### | 100%
xz 5.2.3: ############################################################## | 100%
zlib 1.2.11: ########################################################### | 100%
pip 9.0.1: ############################################################# | 100%
libcxx 4.0.1: ########################################################## | 100%
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use:
# > source activate tutorialConda
#
# To deactivate an active environment, use:
# > source deactivate
#
Activation
Much like virtualenv, you must activate your newly created environment. The command below will activate your environment on Linux.
(tutorialConda) Bradleys-Mini:~ BradleyPatton$
Installing Packages
The conda list command will list the packages currently installed to your project. You can add additional packages and their dependencies with the install command.
#
# Name Version Build Channel
ca-certificates 2017.08.26 ha1e5d58_0
certifi 2018.1.18 py36_0
libcxx 4.0.1 h579ed51_0
libcxxabi 4.0.1 hebd6815_0
libedit 3.1 hb4e282d_0
libffi 3.2.1 h475c297_4
ncurses 6.0 hd04f020_2
openssl 1.0.2n hdbc3d79_0
pip 9.0.1 py36h1555ced_4
python 3.6.4 hc167b69_1
readline 7.0 hc1231fa_4
setuptools 38.4.0 py36_0
sqlite 3.22.0 h3efe00b_0
tk 8.6.7 h35a86e2_3
wheel 0.30.0 py36h5eb2c71_1
xz 5.2.3 h0278029_2
zlib 1.2.11 hf3cbc9b_2
To install pandas into the current environment you would execute the below shell command.
It will download and install the relevant packages and dependencies.
package | build
—————————|—————–
libgfortran-3.0.1 | h93005f0_2 495 KB
pandas-0.22.0 | py36h0a44026_0 10.0 MB
numpy-1.14.0 | py36h8a80b8c_1 3.9 MB
python-dateutil-2.6.1 | py36h86d2abb_1 238 KB
mkl-2018.0.1 | hfbd8650_4 155.1 MB
pytz-2017.3 | py36hf0bf824_0 210 KB
six-1.11.0 | py36h0e22d5e_1 21 KB
intel-openmp-2018.0.0 | h8158457_8 493 KB
————————————————————
Total: 170.3 MB
The following NEW packages will be INSTALLED:
intel-openmp: 2018.0.0-h8158457_8
libgfortran: 3.0.1-h93005f0_2
mkl: 2018.0.1-hfbd8650_4
numpy: 1.14.0-py36h8a80b8c_1
pandas: 0.22.0-py36h0a44026_0
python-dateutil: 2.6.1-py36h86d2abb_1
pytz: 2017.3-py36hf0bf824_0
six: 1.11.0-py36h0e22d5e_1
By executing the list command again, we see the new packages install in our virtual environment.
# packages in environment at /Users/BradleyPatton/anaconda/envs/tutorialConda:
#
# Name Version Build Channel
ca-certificates 2017.08.26 ha1e5d58_0
certifi 2018.1.18 py36_0
intel-openmp 2018.0.0 h8158457_8
libcxx 4.0.1 h579ed51_0
libcxxabi 4.0.1 hebd6815_0
libedit 3.1 hb4e282d_0
libffi 3.2.1 h475c297_4
libgfortran 3.0.1 h93005f0_2
mkl 2018.0.1 hfbd8650_4
ncurses 6.0 hd04f020_2
numpy 1.14.0 py36h8a80b8c_1
openssl 1.0.2n hdbc3d79_0
pandas 0.22.0 py36h0a44026_0
pip 9.0.1 py36h1555ced_4
python 3.6.4 hc167b69_1
python-dateutil 2.6.1 py36h86d2abb_1
pytz 2017.3 py36hf0bf824_0
readline 7.0 hc1231fa_4
setuptools 38.4.0 py36_0
six 1.11.0 py36h0e22d5e_1
sqlite 3.22.0 h3efe00b_0
tk 8.6.7 h35a86e2_3
wheel 0.30.0 py36h5eb2c71_1
xz 5.2.3 h0278029_2
zlib 1.2.11 hf3cbc9b_2
For packages not part of the Anaconda repository, you can utilize the typical pip commands. I won’t cover that here as most Python users will be familiar with the commands.
Anaconda Navigator
Anaconda includes a GUI based navigator application that makes life easy for development. It includes the spyder IDE and jupyter notebook as preinstalled projects. This allows you to fire up a project from your GUI desktop environment quickly.

In order to begin working from our newly created environment from the navigator, we must select our environment under the tool bar on the left.

We then need to install the tools that we would like to use. For me this is namely spyder IDE. This is where I do most of my data science work and to me this is an efficient and productive Python IDE. You simply click the install button on the dock tile for spyder. Navigator will do the rest.

Once installed, you can open the IDE from the same dock tile. This will launch spyder from your desktop environment.

Spyder

spyder is the default IDE for Anaconda and is powerful for both standard and data science projects in Python. The spyder IDE has an integrated IPython notebook, a code editor window and console window.
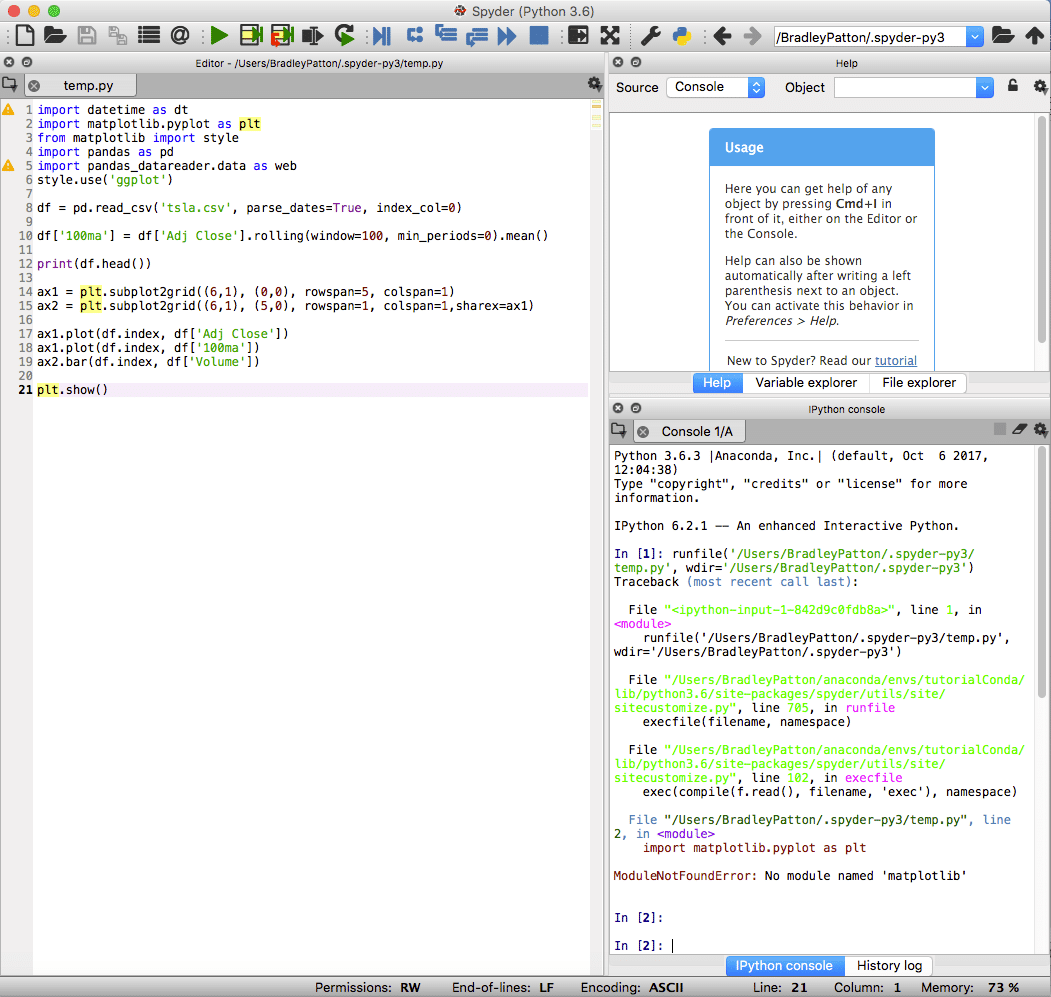
Spyder also includes standard debugging capabilities and a variable explorer to assist when something doesn’t go exactly as planned.
As an illustration, I have included a small SKLearn application that uses random forrest regression to predict future stock prices. I have also included some of the IPython Notebook output to demonstrate the usefulness of the tool.
I have some other tutorials I have written below if you would like to continue exploring data science. Most of these are written with the help of Anaconda and spyder abnd should work seamlessly in the environment.
from pandas_datareader import data
import numpy as np
import talib as ta
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
def get_data(symbols, start_date, end_date, symbol):
panel = data.DataReader(symbols, ‘yahoo’, start_date, end_date)
df = panel[‘Close’]
print(df.head(5))
print(df.tail(5))
print df.loc["2017-12-12"]
print df.loc["2017-12-12", symbol ]
print df.loc[: , symbol ]
df.fillna(1.0)
df["RSI"] = ta.RSI(np.array(df.iloc[:,0]))
df["SMA"] = ta.SMA(np.array(df.iloc[:,0]))
df["BBANDSU"] = ta.BBANDS(np.array(df.iloc[:,0]))[0]
df["BBANDSL"] = ta.BBANDS(np.array(df.iloc[:,0]))[1]
df["RSI"] = df["RSI"].shift(–2)
df["SMA"] = df["SMA"].shift(–2)
df["BBANDSU"] = df["BBANDSU"].shift(–2)
df["BBANDSL"] = df["BBANDSL"].shift(–2)
df = df.fillna(0)
print df
train = df.sample(frac=0.8, random_state=1)
test = df.loc[~df.index.isin(train.index)]
print(train.shape)
print(test.shape)
# Get all the columns from the dataframe.
columns = df.columns.tolist()
print columns
# Store the variable we’ll be predicting on.
target = symbol
# Initialize the model class.
model = RandomForestRegressor(n_estimators=100, min_samples_leaf=10, random_state=1)
# Fit the model to the training data.
model.fit(train[columns], train[target])
# Generate our predictions for the test set.
predictions = model.predict(test[columns])
print "pred"
print predictions
#df2 = pd.DataFrame(data=predictions[:])
#print df2
#df = pd.concat([test,df2], axis=1)
# Compute error between our test predictions and the actual values.
print "mean_squared_error : " + str(mean_squared_error(predictions, test[target]))
return df
def normalize_data(df):
return df / df.iloc[0,:]
def plot_data(df, title="Stock prices"):
ax = df.plot(title=title,fontsize = 2)
ax.set_xlabel("Date")
ax.set_ylabel("Price")
plot.show()
def tutorial_run():
#Choose symbols
symbol = "EGRX"
symbols = [symbol]
#get data
df = get_data(symbols, ‘2005-01-03’, ‘2017-12-31’, symbol)
normalize_data(df)
plot_data(df)
if __name__ == "__main__":
tutorial_run()
EGRX RSI SMA BBANDSU BBANDSL
Date
2017-12-29 53.419998 0.000000 0.000000 0.000000 0.000000
2017-12-28 54.740002 0.000000 0.000000 0.000000 0.000000
2017-12-27 54.160000 0.000000 0.000000 55.271265 54.289999


Conclusion
Anaconda is great environment for data science and machine learning in Python. It comes with a repo of curated packages that are designed to work together for a powerful, stable and reproducible data science platform. This allows a developer to distribute their content and ensure that it will produce the same results across machines, and operating systems. It comes with built-in tools to make life easier like the Navigator, which allows you to easily create projects and switch environments. It is my go-to for developing algorithms and creating projects for financial analysis. I even find that I use for most of my Python projects because I am familiar with the environment. If you are looking to get started in Python and data science, Anaconda is a good choice.