What is YUM?
YUM is a management tool that is available on RedHat and CentOS Linux distros. YUM (Yellowdog Updater Modified) is dependent on RPM (Red Hat Package Manager) packages, and was created to enable the management of packages as parts of a larger system of software repositories instead of individual package files. YUM is a interactive package manager that can automatically perform dependency analysis and system updates, along with installing new packages, removing old packages, performing queries on existing packages, etc. To know more about YUM, click here.
In this article we will look at methods of accessing yum functionality using Python programs and find out how it can be useful. For this tutorial, we will use CENTOS 7 running python 2.7.x and would assume some familiarity with basic python features.
Programming with YUM
Let’s begin learning about programming yum using python by looking at a simple python script that uses yum to query and print package names. Here it is:
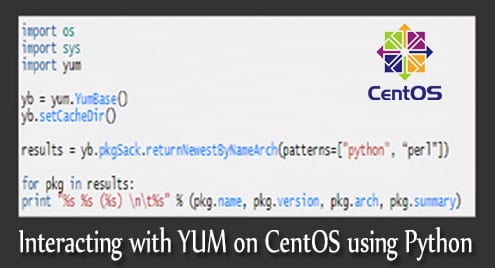
import sys
import yum
yb = yum.YumBase()
yb.setCacheDir()
results = yb.pkgSack.returnNewestByNameArch(patterns=["python", “perl”])
for pkg in results:
print "%s %s (%s) nt%s" % (pkg.name, pkg.version, pkg.arch, pkg.summary)
This scripts searches the YUM repositories for packages matching the name “python” and prints information about the matched package(s). We will examine this script line-by-line.
To start programming with YUM, we need to import the `yum` python package – this is installed by default in CENTOS 7. Along with `yum` we usually need the `os` and `sys` packages as well – so a typical python program using yum would begin with the following 3 lines.
import sys
import yum
Next, to create a yum instance to work with, include the below line.
This is almost the first line of functional code in any python program using yum. That is because, YumBase is the base class that houses methods and objects required to perform all the package management functions using yum. For the detailed structure of the YumBase class, refer to its documentation.
Examining YUM configuration
Once an instance of YumBase is available we can use that to inspect the yum configuration. Below is a table listing popular commands for listing the configuration details.
| Configuration | Usage |
| print yb.conf.config_file_path | Print the file path for yum’s config file. |
| print yb.conf.logfile | To printout the logfile’s path |
| for i in yb.conf.reposdir : print i | To printout the directories and files for the repositories |
| print yb.conf.skip_broken | The value is usually false. When set to true, yum commands will act as if the –skip-broken parameter was supplied. |
| print yb.conf.errorlevel | To set the level of errors you’d like to see printed on the standard output. It’s a value between 0-10 where 0 is only critical , while 10 is everything include debug. By default it is set to 2, but you can override it. If you’ll be running in a script, it’s a good idea to set this to 0. You can set this to a greater value like 3 when you are debugging the script itself. |
Querying for packages
Returning to our script, we see the next line of code is setting up a new Cache Directory for yum so it performs all tasks as a normal user (and also as the root user to some extent – it still wont be able to alter data in the yumdb or rpmdb for example).
Having created a real yum object now, we can access the pkgSack, rpmdb and repos attributes. This allows us to perform the followig functions:
yb.pkgSack – can be used to perform queries on all the enabled repositories
yb.rpmdb – can be used to perform queries on the installed packages
yb.repos – get a RepositoryStorage object that can be used to set specific configurations for the repos and can be used to enable or disable repositories – e.g., yb.repos.enableRepo(), yb.repos.disableRepo() & yb.repos.listEnabled(). More on this later.
For now we will delve into the pkgSack and rpmdb properties. We can search the YUM repositories & locally installed packages respectively by calling one of the several functions provided by the pkgSack and rpmdb attributes. These functions return “package objects” that contain information about the package. Some useful functions to get the package objects are: returnPackages(), searchPrimaryFields(), seachNevra(), seachName() , returnNewestByNameArch(). Our script uses the returnNewstByNameArch method to get the package objects matching the pattern strings “python” or “perl”.
Note that the method names are same for both yb.rpmdb and yb.pkgSack. However, they perform the queries on different domains – rpmdb searches the local installed RPM packages database whereas pkgSack searches the YUM repositories.
We could, similarly list the large packages installed (where large means, say size is >10MB). The yum code is:
l_plist = [p for p in plist if p.size > 1024 * 1024 * 10]
print "Installed packages with size > 10MB:"
for p in l_plist:
print "%s: %sMB" % (pkg, pkg.size / (1024 * 1024))
That is basically the essence of using python to access yum. In the rest of the article we will delve deeper into the nuances of the yum module API and tryout some more complication actions like installing / uninstalling packages or setting up our own repository.
Nevra, PRCO and Tuples
There is no typo in the heading – these are some yum specific terms that make identifying packages and dependencies easier as well as in communicating these with other users of yum, including your python scripts.
NEVRA stands for Name, Epoch, Version, Release, Architecture and is used to uniquely identify a flavor or instance of a package – these five parameters together unambiguously point to one unique instance of the package. For example, a package called “python” may have multiple versions like 2.6, 2.7 etc., and each version could have multiple releases for different architectures e.g., x86_64, i386 (Note that the word architecture here refers to the CPU architecture – e.g., i386 is 32-bit Intel). Together these five represent a unique combination and is referred to as nevra.
PRCO stands for Provides/Requires/Conflicts/Obsoletes which summarize the package management metadata for the package object.
Certain API methods in pkgSack/ rpmdb, like yb.pkgSack.simplePkgList(), yb.pkgSack.packagesByTuple() etc., return NEVRA or PRCO information as python tuples rather than pkgobjects
List and install packages
Akin to using “yum list” command, we can use `yb.doPackageLists()` to list all the packages installed/ packages available for install /re-install.
Now plist contains 3 package lists – one each for installed package, installable package and those avaialble for reinstall. We can print/install/reinstall packages using the code below:
print "Installed Packages"
for pkg in sorted(pl.installed):
print pkg
if pl.available:
print "Available Packages"
for pkg in sorted(pl.available):
print pkg, pkg.repo
if pl.reinstall_available:
print "Re-install Available Packages"
for pkg in sorted(pl.reinstall_available):
print pkg, pkg.repo
Similarly to list all the installed packages we can use:
Installing packages
Installing packages involves setting up and executing a transaction. To perform simple actions like install/ remove we use the `yb.install` or `yb.remove` respectively to setup the transaction. Then we invoke the `yb.resolveDeps()` to trigger the resolution of dependencies and `yb.processTransaction()` to instruct YUM to go ahead and execute the transaction.
All steps, but the last one, are preparatory and only the call to the processTransaction() method actually results in the installation/ uninstallation to happen. Below is a code-snippet for package installation.
yb.install(name=‘packagename’)
yb.resolveDeps()
yb.processTransaction()
While performing such transactions the `yb.tsInfo` object holds the information about the current status of the transaction until it is committed. You can read more about it in its documentation.
Setup a repository at an arbitrary location
Below script helps you setup yum to access a repository at an arbitrary location. It expects the URL of the repository to be passed in as the command line argument.
yb = yum.YumBase()
if not yb.setCacheDir(force=True, reuse=False):
print >>sys.stderr, "Can’t create a tmp. cachedir. "
sys.exit(1)
yb.repos.disableRepo(‘*’)
yb.add_enable_repo(‘myrepo’, [url])
To run the script
Summary
In this article we learnt how to control the YUM package manager using its python API. We looked at the configuration options as well as the query/ search APIs on the available and installed packages and finally at ways to perform package management operations such as installing/ uninstalling/ reinstalling packages.
This article is intended to serve as a window into what is possible via the yum python API. Although the API is not very well documented, it follows standard conventions and works predictably. Armed with the knowledge of YUM’s capabilities and python skills it’s fun to explore and learn everything it can do. Hope you enjoyed reading so far and that you continue with your exploration & application of yum in your projects.

